浅谈交叉熵
2022-01-08 14:41:23 机器学习 编辑:黎为乐
I(x0)=-log(p(x0))
我们来看看这个函数的图像长什么样
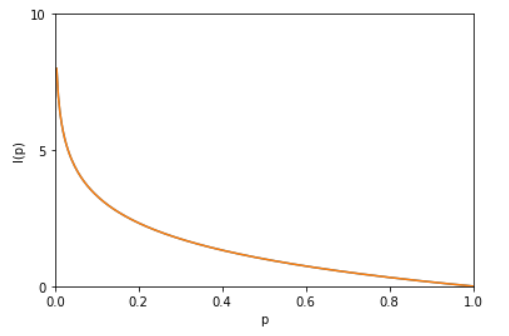
x轴是概率p(x0),y轴是信息量I(x0),结合图像看看,这就是不确定性越大,信息量越大了
说完了信息量,我们来看看熵是什么,信息量是对于单个事件来说的,而现实世界中,是有很多中可能发生的,比如就拿天气来说,可能明天会下雪,下雨或者是晴天。引用网上大佬的专业术语:熵是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。公式如下:
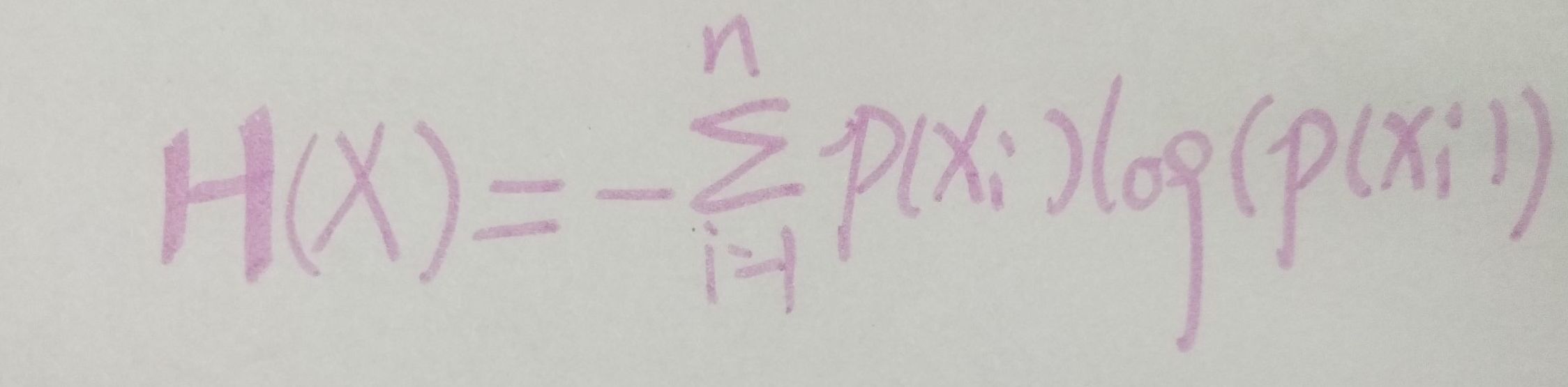
如果你不知道期望是什么,请看下图:
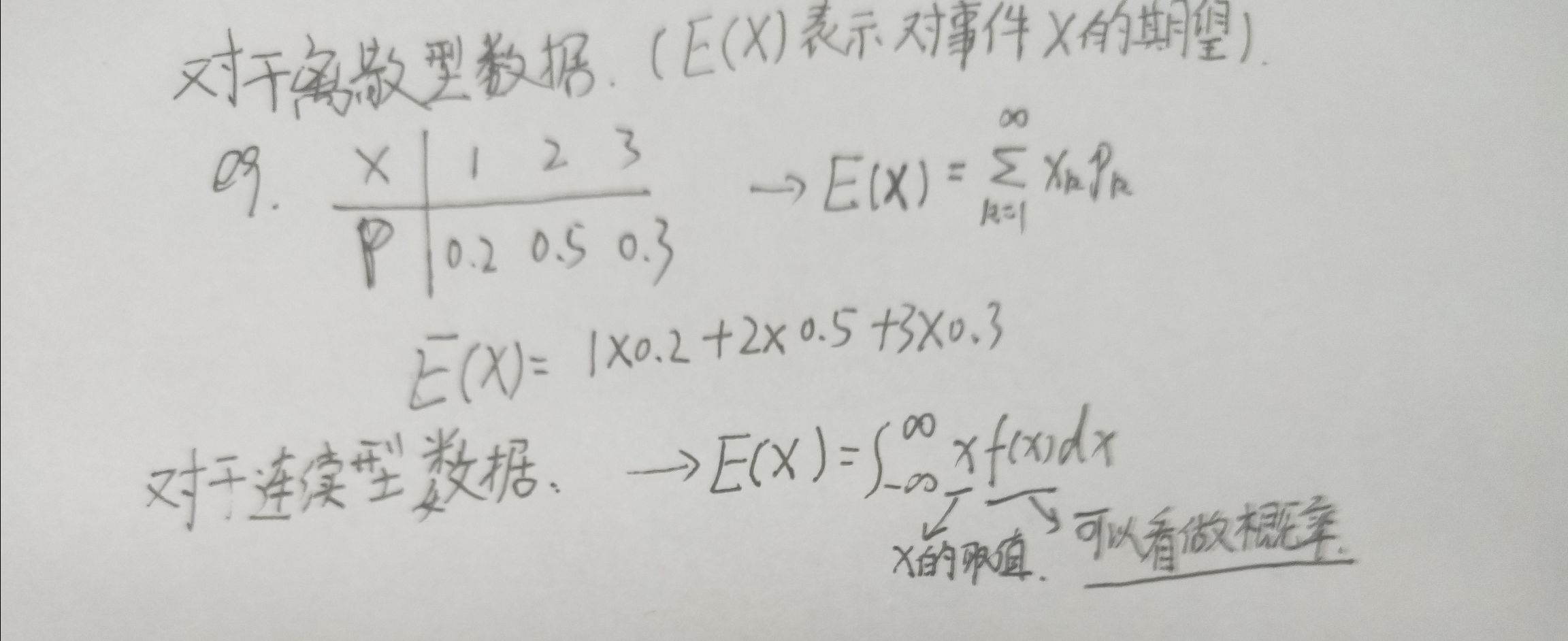
看完了期望,我们再来看看上面的式子,p(x(i))就是某个可能的概率,-log(p(xi))是信息量。你可以花点时间来慢慢理解。
我们再看看特殊情况,即事件X服从(二项分布,0-1分布),你可以不知道这两个是什么分布,我来举个例子,比如投掷硬币,只有正反两面,那么上式可以写作:
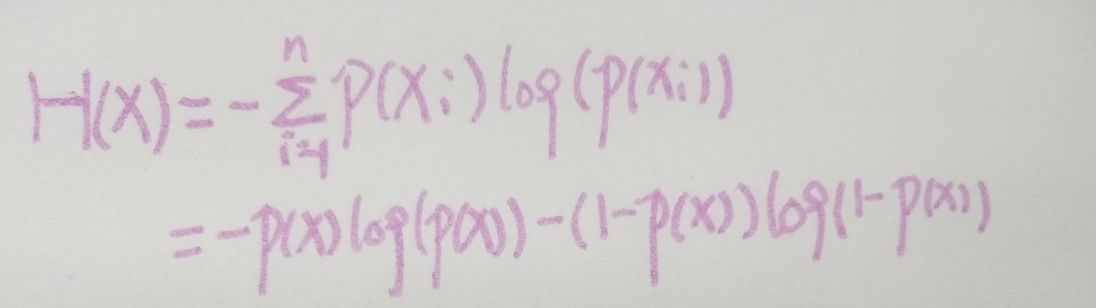
两种可能,那么第一种可能的概率为p(x),第二种的可能就是1-p(x),这很好理解
我们再来看看相对熵(KL散度)用于衡量对于同一个随机变量x的两个分布p(x)和q(x)之间的差异。我们来举个例子来解释这句话是什么意思。p(x)和q(x)分别为真实分布和预测分布,假如的对于一组数据,他的真实分布为[1,0,0,0],我们预测的分布q(x)为[0.7,0.1,0.1,0.1],这个预测的效果其实已经不错了,但还是不够准确,q(x)需要不断的去拟合这个p(x),我们再来看看经过不知道多少轮训练过后,q(x)分布为[0.991,0.002,0.003,0.001],这个就已经很接近p(x)的分布了。说完这些我们来看公式
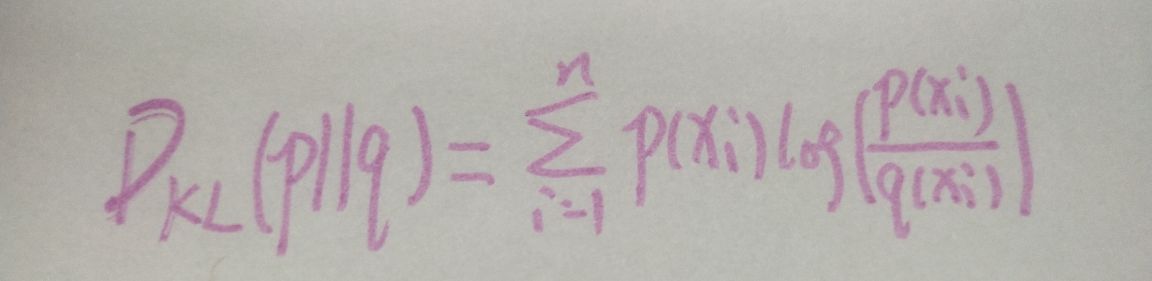
即KL散度的值越小两个分布越接近
说了那么多,我们来看一下KL散度的变形:
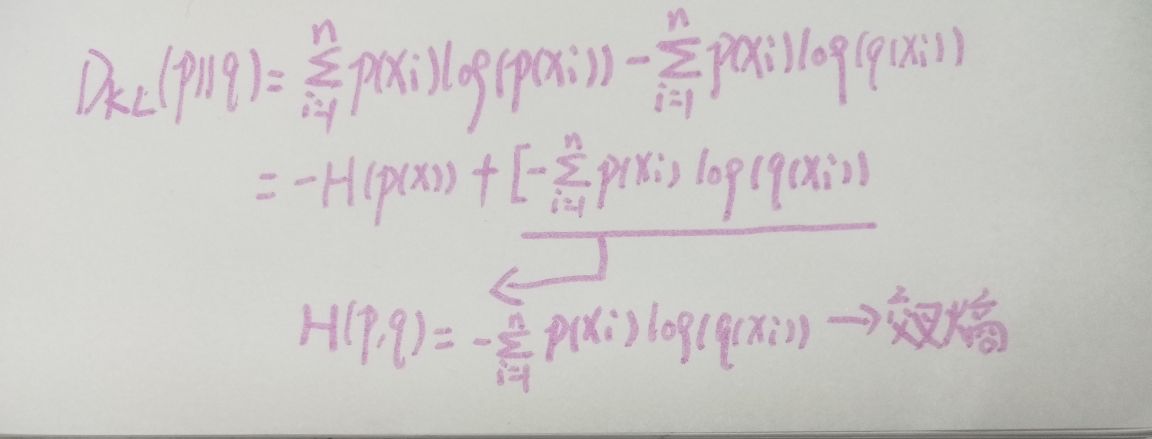
在机器学习中,我们经常使用KL散度来评估预测值与实际值的差别,KL的前半部分是一个常量,所以我们就将后半部分的交叉熵来作为损失函数,这两者没有什么区别。我已经尽可能详细的说明了交叉熵这个概念,如果你还不明白,那我不能像上面那篇文章给你一个那么清晰的图片了。